
OpenAI Assistants API 可帮助开发人员轻松在其应用程序中创建强大的 AI 助手。该 API 具有以下功能/特性:
- 消除了处理对话历史的需要,
- 提供了访问 OpenAI 托管工具(如代码解释器和检索)的入口,
- 增强了对第三方工具的函数调用。
在本文中,我们将介绍 Assistants API 以及如何使用像 MyScale 这样的向量数据库构建自定义知识库,并将其与 Assistants API 进行关联,以实现更大的灵活性、准确性和成本节约。
![]()
![]()
# 什么是 OpenAI Assistant?
OpenAI Assistant 是一个自动化工作流,可以利用大型语言模型(LLM)、工具和知识库来回答用户的查询。正如上面所提到的,您必须使用 Assistants API 来创建一个 OpenAI Assistant。
让我们首先来看一下 Assistants API 的内部结构:
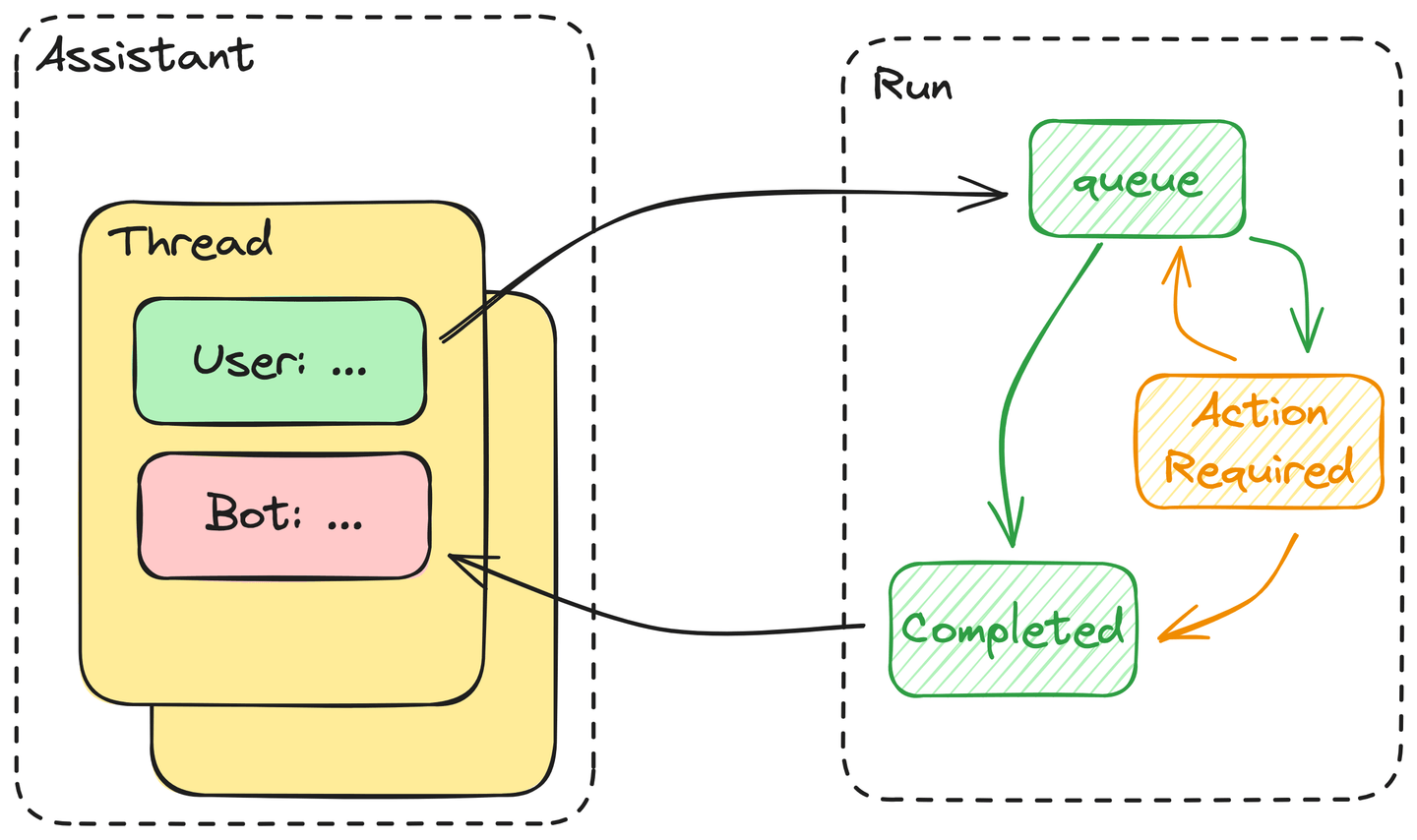
# 组件
Assistants API 由以下核心组件组成:
- Assistant:Assistant 包含它可以使用的工具的定义、它可以读取的文件以及它将附加到其中的线程的系统提示。
- Thread:线程由控制助手对话的消息组成。
- Messages:消息是构成线程的基本元素,包含所有文本,包括用户的输入和生成的答案。
- Run:用户每次从助手请求答案时都必须启动一个运行。实际上,助手会执行线程中的所有消息。如果需要执行任何操作,则用户必须将工具的输出提交给运行。
# 使用 Assistants API 的工具启动运行
这是人工智能的一个指示,因为这些助手知道如何使用通过 API 调用提供的工具。为此,OpenAI 已经证明 GPT 可以通过传递给 API 的函数调用将用户请求转换为格式化的使用工具。因此,从人类的角度来看,这相当于知道如何使用工具。
此外,这些助手可以在单个运行的执行过程中决定何时以及使用哪些工具。如果我们简化这个过程,我们会发现:
- 用户启动运行后,线程中的所有消息将被排队。一旦有资源可用来处理它们,这些消息将从队列中取出。
- 然后,助手将决定是否使用助手定义中提供的任何工具。如果是这样,助手将进入
ActionRequired状态,直到提供所需的操作为止。如果不是这样,助手将立即返回答案,并将此运行标记为Completed。 - 助手将等待工具调用的输出,直到超过超时阈值。如果一切按计划进行,助手将将工具的输出附加到线程中,返回答案,并将运行标记为已完成,如上所述。
总之,运行的执行基本上是由 LLM 驱动的自动机。
# 将 MyScale 链接到 OpenAI 的助手
MyScale 具有 SQL 接口,这是自动化查询的一个重要优势。此外,LLM 擅长编写代码,包括 SQL。因此,我们将 SQL WHERE 过滤器与向量搜索相结合,如我们的函数调用文档 (opens new window)中所述。
现在,让我们考虑将这个函数调用扩展为 MyScale 和 OpenAI Assistants API 之间的链接。
# 永远不要使用助手的检索工具
OpenAI 在 Assistants API 中包含了一个检索工具,每天的费用为 $0.2 / (GB * num_assistants)。以 Arxiv 数据集为例:其数据约为 24GB,包括嵌入。这将使您每天花费 $5(每月 $150)仅用于一个助手。此外,您永远不知道检索性能在准确性和时间消耗方面如何。如果您有大量数据需要存储和搜索,那么外部向量数据库是必不可少的。
# 将知识库定义为助手的工具
根据 Assistants API 的官方文档,您可以使用 OpenAI().beta.create_assistants.create 创建一个助手。如果您想使用现有的知识库构建助手,下面是一个示例:
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create(
name="ChatData",
instructions=(
"You are a helpful assistant. Do your best to answer the questions. "
),
tools=[
{
"type": "function",
"function": {
"name": "get_wiki_pages",
"description": (
"Get some related wiki pages.\n"
"You should use schema here to build WHERE string:\n\n"
"CREATE TABLE Wikipedia (\n"
" `id` String,\n"
" `text` String, -- abstract of the wiki page. avoid using this column to do LIKE match\n"
" `title` String, -- title of the paper\n"
" `view` Float32,\n"
" `url` String, -- URL to this wiki page\n"
"ORDER BY id\n"
"You should avoid using LIKE on long text columns."
),
"parameters": {
"type": "object",
"properties": {
"subject": {"type": "string", "description": "a sentence or phrase describes the subject you want to query."},
"where_str": {
"type": "string",
"description": "a sql-like where string to build filter.",
},
"limit": {"type": "integer", "description": "default to 4"},
},
"required": ["subject", "where_str", "limit"],
},
},
}
],
model="gpt-3.5-turbo",
)
暴露的函数有三个输入:subject、where_str 和 limit,与 MyScale 中的向量存储 (opens new window) 的实现相匹配。
如提示中所述:
subject是用于向量搜索的文本,where_str是以 SQL 格式编写的结构化过滤器。
我们还在工具描述中添加了表模式,以帮助助手使用正确的 SQL 函数编写过滤器。
# 将 MyScale 的外部知识注入助手
要将 MyScale 的外部知识注入到我们的助手中,我们需要一个工具来根据助手生成的参数检索此知识。例如,我们将实现简化的 MyScale 向量存储,如下所示:
import clickhouse_connect
db = clickhouse_connect.get_client(
host='msc-950b9f1f.us-east-1.aws.myscale.com',
port=443,
username='chatdata',
password='myscale_rocks'
)
must_have_cols = ['text', 'title', 'views']
database = 'wiki'
table = 'Wikipedia'
def get_related_pages(subject, where_str, limit):
q_emb = emb_model.encode(subject).tolist()
q_emb_str = ",".join(map(str, q_emb))
if where_str:
where_str = f"WHERE {where_str}"
else:
where_str = ""
q_str = f"""
SELECT dist, {','.join(must_have_cols)}
FROM {database}.{table}
{where_str}
ORDER BY distance(emb, [{q_emb_str}])
AS dist ASC
LIMIT {limit}
"""
docs = [r for r in db.query(q_str).named_results()]
return '\n'.join([str(d) for d in docs])
tools = {
"get_wiki_pages": lambda subject, where_str, limit: get_related_pages(subject, where_str, limit),
}
其次,我们需要一个新的线程来保存我们的输入:
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What is Ring in mathematics? Please query the related documents to answer this.",
)
client.beta.threads.messages.list(thread_id=thread.id)
运行是从线程创建的,并与特定的助手关联。不同的运行可以有不同的助手。因此,一个线程可以包含使用不同工具生成的消息。
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions= "You must use query tools to look up relevant information for every answer to a user's question.",
)
重要的是要不断检查此运行的状态,并为助手调用的每个函数提供输出。
import json
from time import sleep
while True:
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
if run.status == 'completed':
print(client.beta.threads.messages.list(thread_id=thread.id))
# 如果运行已完成,则无需做任何事情
break
elif len(run.required_action.submit_tool_outputs.tool_calls) > 0:
print("> Action Required <")
print(run.required_action.submit_tool_outputs.tool_calls)
# 如果运行需要操作,则需要运行工具并提交输出
break
sleep(1)
tool_calls = run.required_action.submit_tool_outputs.tool_calls
outputs = []
# 为每个所需操作调用工具
for call in tool_calls:
func = call.function
outputs.append({"tool_call_id": call.id, "output": tools[func.name](**json.loads(func.arguments))})
if len(tool_calls) > 0:
# 提交所有待处理的输出
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=outputs
)
一旦输出被提交,运行将重新进入“排队”状态。
注意: 我们还需要不断检查此运行的状态。
from time import sleep
while client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
).status != 'completed':
print("> waiting for results... <")
sleep(1)
messages = client.beta.threads.messages.list(thread_id=thread.id).data[0].content[0].text.value
print("> generated texts <\n\n", messages)
最后,这个示例演示了如何使用 Assistants API。

# 结论
总之,将 MyScale 向量数据库作为外部知识库与 OpenAI 的 Assistants API 结合使用,为寻求增强其 AI 助手的开发人员打开了新的视野。通过无缝整合这个宝贵的资源,开发人员可以与 OpenAI 托管的工具(如代码解释器和检索)一起利用 MyScale 的强大功能。
这种协同作用不仅简化了开发过程,还使 AI 助手拥有更广泛的知识库,为用户提供更强大、更智能的体验。随着我们在人工智能研究中的不断进步,这样的集成标志着朝着创建多功能和有能力的虚拟助手迈出了重要的一步。
立即加入我们的 Discord (opens new window),与我们分享您对 Assistants API 的想法!



