
# 关于Testin

Testin成立于2011年,是一家企业服务平台,提供两项主要服务:为开发人员提供的云测试服务,已为超过80万名开发人员提供服务,并为200万个应用程序执行了超过1.5亿次测试;以及机器学习(ML)模型训练服务,包括数据标注和模型部署等服务,涉及安全、物联网(IoT)等行业。迄今为止,Testin已与110多家公司合作,涵盖了从提供自动驾驶技术的汽车制造商到处理面部识别和自然语言处理应用的智能家居和金融公司。Testin还获得了中国多个知名奖项,包括德勤中国高科技50强和Red Herring全球100强。
# 在使用MyScale之前
MyScale与Testin合作,寻找使AI数据标注服务尽可能有用的新方法。典型的Testin AI数据标注平台用户将经历以下步骤:
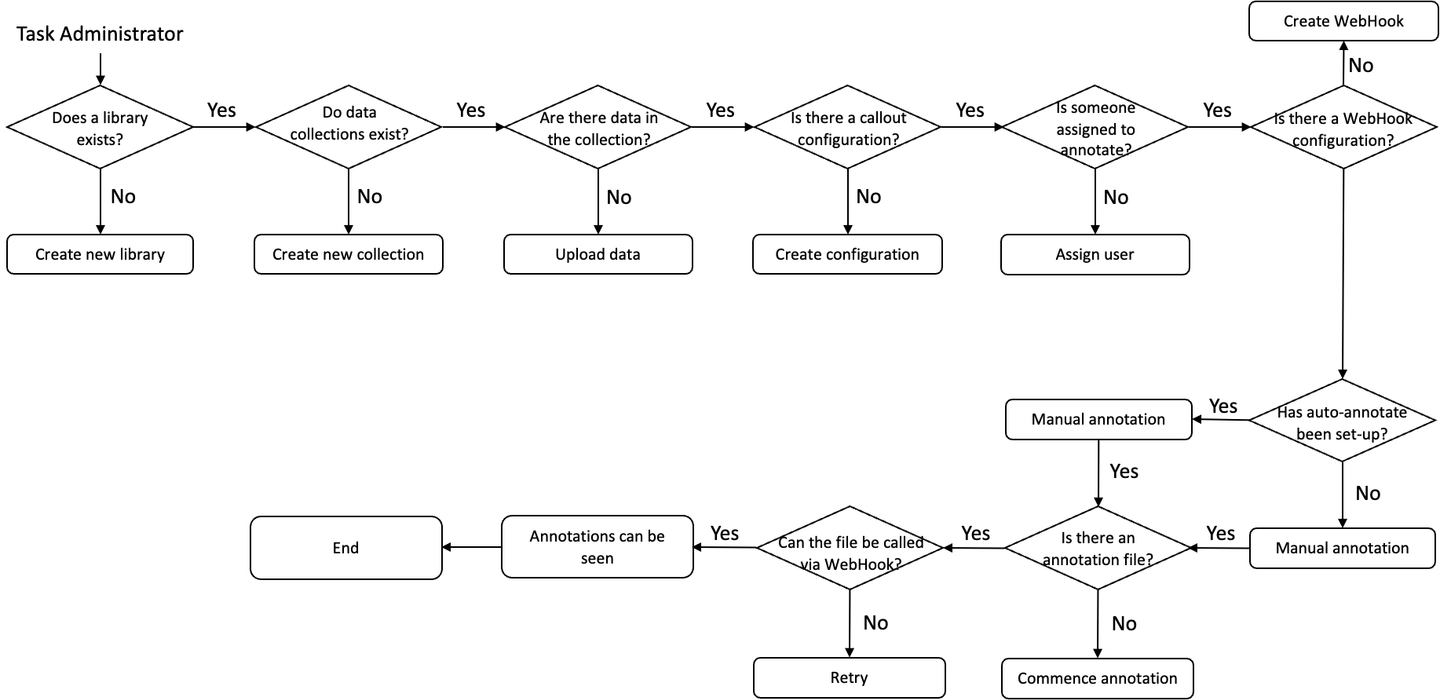
用户首先在库中创建一个集合。之后,数据被添加到集合中,然后才能开始对数据进行标注。AI数据标注平台将数据导出供其他应用程序使用,例如机器学习模型。
虽然数据标注的过程看起来很简单,但却是耗时的。例如,尽管Testin的自动标注功能可以帮助用户节省标注时间,但并不总是可靠的。如图所示,该平台只能识别一辆汽车,无法识别其他汽车或较大的车辆,如公交车。由于在所有图像上缺乏一致且高质量的标注,只有少数图像具有准确的标注。

另一方面,如果用户希望进行标注,这将是耗时的,但标注的质量会得到提高。在这个过程中,用户必须手动识别和分类与自动驾驶汽车相关的图像区域。然而,对于大多数用户来说,手动标注大批量的图像是不切实际的。因此,用户通常需要从自动标注的照片中选择,并提高标注的质量。
当前流程的另一个问题是数据及其标注无法无缝地从一个平台转移到另一个平台。Testin AI数据平台的用户目前无法选择将所有标注存储在他们选择的云驱动器上以便访问。他们必须将标注下载到本地驱动器,然后才能执行相似性搜索或训练他们的AI模型。
# 利用MyScale在Testin AI数据平台上的向量搜索功能
因此,MyScale建议Testin考虑对其AI数据平台进行两个更改:
利用MyScale的无监督学习功能进行小样本处理
Testin用户可以从本地设备和云设备上的MyScale平台执行联合查询。
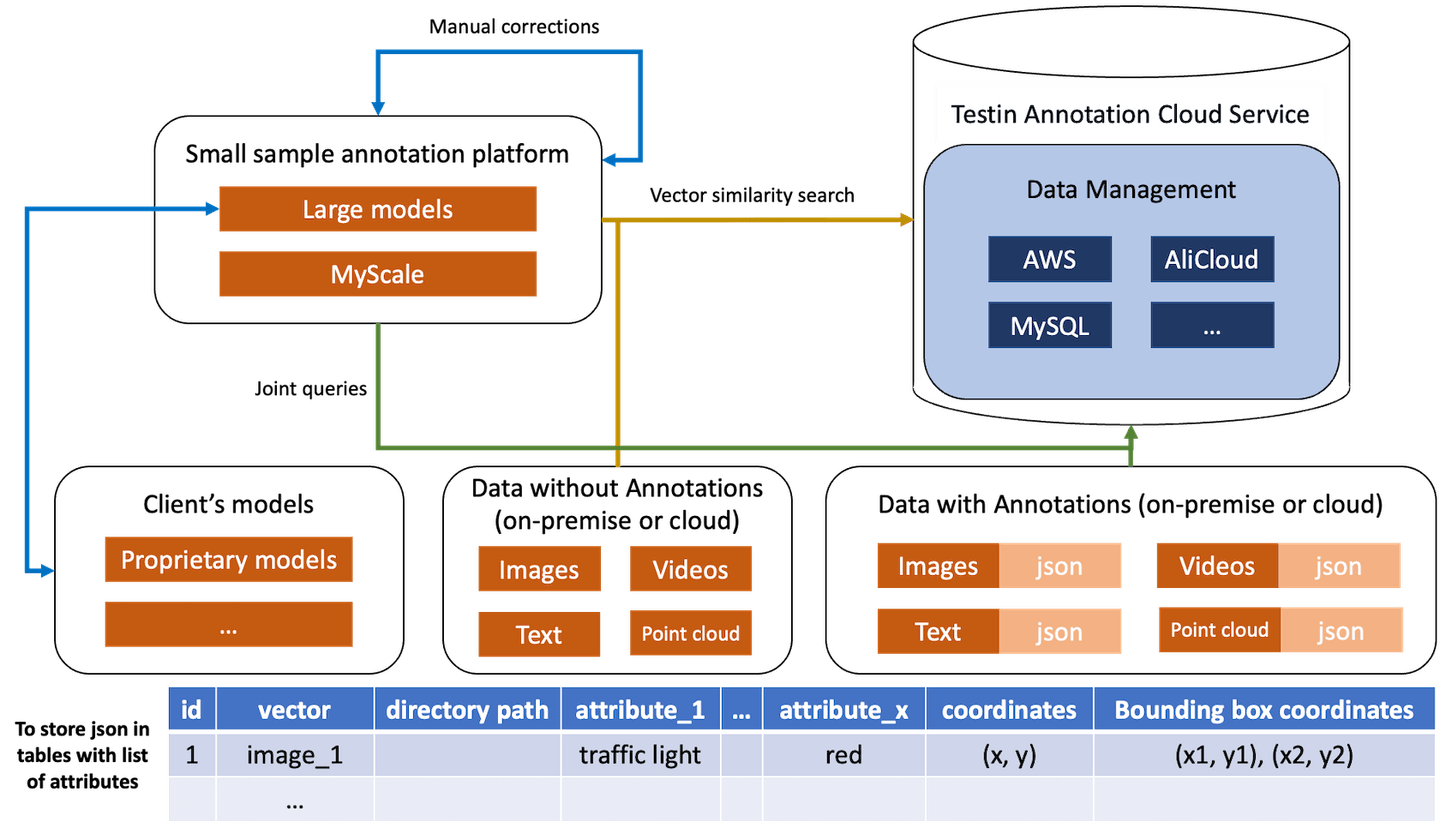
对于前者,MyScale允许用户从带有或不带有标注的图像批次中选择特定图像,以确定它们是否需要对标注进行进一步处理。这意味着使用Testin的自动标注功能的用户可以使用MyScale快速搜索标注批次,并确定哪些图像具有良好/差(或没有)标注,而不是手动检查图像并确定批次图像是否与带有标注的高质量样本照片匹配。当对不断更新的照片库进行标注时,这也非常有用,使用MyScale可以避免用户必须筛选图像以确定是否需要标注。
对于后者,用户可以使用MyScale平台的SQL查询功能,从他们链接的云数据库帐户和本地提供的向量文件中执行向量相似性搜索,以与查询向量匹配。例如,如果查询是一张照片或文本,MyScale将搜索相似的文本和照片,以及相似的视频和其他数据模态。此外,当发现两个高相似度的向量时,Testin使用此功能来过滤重复数据。

# MyScale如何帮助您通过向量搜索解锁新的商业价值
MyScale与软件测试公司Testin合作,改进了他们的数据标注工作流程。Testin使用了MyScale的SQL和高性能向量搜索功能,构建了自己的自动数据标注和数据去重功能。虽然手动标注数据很常见,但它也是确保高质量数据标注以及时间和成本性能的瓶颈。MyScale通过使用其SQL功能,协助Testin开发了自动数据标注和数据去重功能。
作为一个适用于开发机器学习模型和应用程序的高性能数据库,Testin通过自动化流程、减少标注时间、存储空间和成本,改进了其数据标注工作流程。
如果您的业务也涉及当前应用程序中的云存储,并且希望了解更多关于MyScale如何帮助您从应用程序和业务中提取更多价值的信息,请随时通过contact@myscale.com与我们联系。



