
# 关于Cowarobot

Cowarobot成立于2015年,是一家专注于为复杂城市环境中的自动驾驶提供一站式解决方案的公司。截至2022年中期,他们在中国的10多个城市设有业务,并拥有1000多辆自动驾驶车辆。他们还与中国的汽车制造商,如樱桃、北汽、陕汽和中联合作,在这些城市开发城市物流配送和交通解决方案。
# 使用MyScale之前
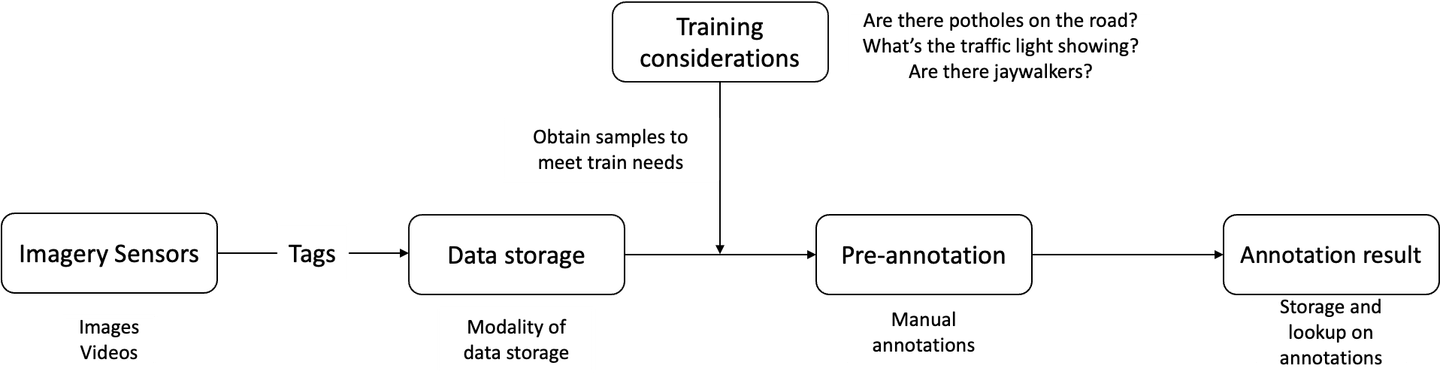
Cowarobot训练自动驾驶车队的主要工作流程分为五个部分:
- 将原始数据和标签存储在集中存储中
Cowarobot专门收集和处理对于自动驾驶车辆至关重要的原始视频和空间数据,如附近车辆、路障和交通信号等动态信息,以及道路表面、人行道、地图和限速等传统数据。数据被标记并组织成多层级的文件夹,然后保存到本地驱动器中。然而,由于产生的数据量巨大,Cowarobot在数据存储方面面临着重大挑战。公司需要采购和维护大量硬盘驱动器,以便以集中、可持续的方式存储数据。此外,为了进行准确的实时物体识别、分割和标签检测,至少需要一百万个数据样本。
- 执行训练任务
Cowarobot使用收集到的原始数据训练模型,使其自动驾驶车辆能够从A点到B点导航,与其他车辆保持安全速度,避免障碍物,并遵守交通信号。为了确保车辆能够应对不断变化的道路条件,训练数据必须不断更新。例如,如果道路标线发生变化,之前的数据标签必须进行修改以反映这些变化。同样,如果车辆遇到新的或意外的情况,如乱穿马路的行人或警察示意停车,它必须经过训练以做出适当的反应。这些更新要求Cowarobot不断获取和标记新数据,以及重新标记现有数据,导致训练成本高昂。这些成本和频繁的更新限制了Cowarobot能够完成的训练任务的类型、频率和质量。
- 获取新样本
Cowarobot无法轻松访问和检索之前为其数据分配的标签,也无法回忆起之前的标签。这个限制意味着公司只能使用其现有数据支持模型训练任务。Cowarobot必须手动从本地驱动器中导出所有数据才能使用,这是一个耗时的过程。此外,现有数据不足以支持Cowarobot模型的训练,因此公司必须继续收集新数据并生成训练样本。然而,当前的工作流程要求Cowarobot在每次更新后手动从本地驱动器中导出所有数据,这是一个繁琐且耗时的过程。
- 数据标签
Cowarobot当前的标签任务流程的手动性质妨碍了生成数据集以更新其模型并部署新更新的效率。这种劳动密集型和耗时的过程阻碍了公司保持其模型与最新数据更新的能力。
- 模型训练
目前,Cowarobot采用分布式架构进行模型训练,即利用多台超级计算机的计算能力进行训练过程的各个阶段。这种策略比使用单个更强大的超级计算机更经济。然而,这种方法的一个缺点是训练样本必须在计算机之间传输,无论是通过网络还是离线,这可能是繁琐和耗时的。
此外,训练模型的输出被低效利用。完成的训练任务将使Cowarobot能够直接在线使用这些模型,但存储在模型训练样本之外的数据尚未更新以反映新模型。
# 采用MyScale作为自动驾驶车辆的数据仓库解决方案
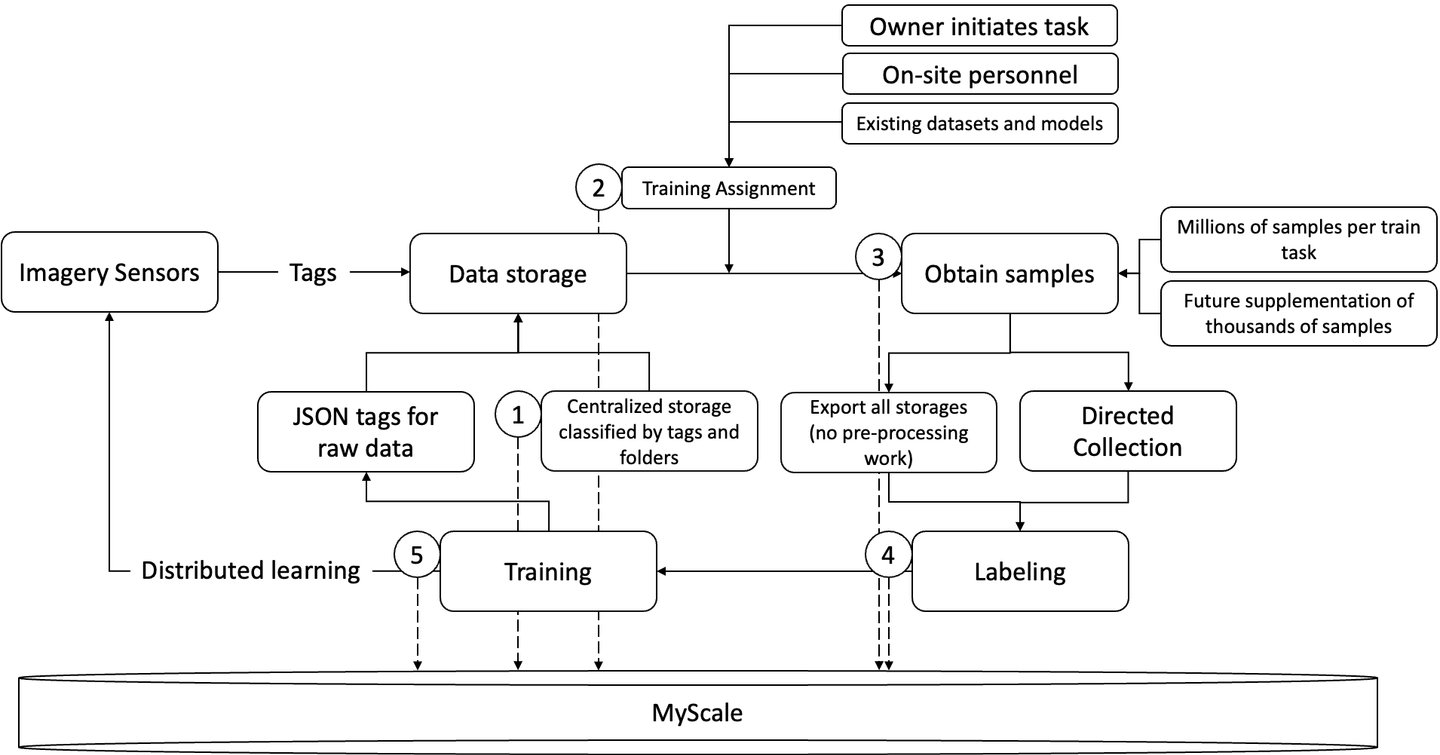
Cowarobot使用MyScale改进了其自动驾驶车辆的模型训练工作流程,涵盖了存储、数据标签和模型训练等方面。
- 将原始数据和标签存储在集中存储中
MyScale提供了一个统一的查询和数据管理存储,数据类型包括ID、向量数据、标签数据、URL等,更容易管理和使用各种目的的数据集。这使得企业内的不同部门能够更好地跟踪他们的机器学习过程,改善数据使用情况,并扩大他们的训练任务范围。
- 执行训练任务
MyScale通过允许用户执行联合SQL查询(属性过滤)来支持从存储数据快速生成训练样本。因此,新的训练任务可能需要更小的样本量,甚至根本不需要获取新数据。这降低了训练成本,并允许用户增加使用较小数据集进行更频繁和更多类型的训练任务。
- 获取新样本
MyScale的一个关键优势是它只需要少量的数据样本。需要更少样本,减少了训练模型所需的获取新样本的工作量。MyScale通过允许用户运行联合SQL查询从存储的数据中快速生成训练样本来实现这一点。如果存在一个具有大量样本的现有数据库,这也是非常有用的,因为MyScale可以筛选训练样本并寻找更高质量的训练样本。这提高了标记数据中正样本的准确性。
- 数据标签
MyScale只需要少量已经标记过的数据样本即可开始模型训练过程。当需要手动更改的数据样本较少时,数据标注所需的时间和成本就会减少。
- 模型训练
MyScale可以管理训练数据并提供完整的SQL支持。MyScale允许用户编写简单的SQL语句直接创建训练样本。模型训练可以直接调用原始数据来开始训练模型的过程。这极大地简化了模型训练任务和从各种来源传输数据的方式。

# MyScale如何帮助您从视频数据中开发新的业务价值

MyScale与无人驾驶出租车公司Cowarobot合作,管理他们的机器学习过程,包括数据收集、存储、获取标签和模型训练。各种数据源,包括向量数据和数据注释,都在一个统一的平台上进行管理。MyScale平台还提供完整的SQL支持,通过只需要一个查询语言来简化模型训练。
MyScale还提供了搜索功能,可以快速从存储的数据中定位训练样本。这降低了训练模型的成本,并改善了训练的频率和方式。Cowarobot利用MyScale和少样本学习进行训练数据筛选、数据分类和数据标记。这种策略减少了所需的数据注释和数据收集量。
如果您的业务当前也涉及图像和视频,并且希望了解更多关于MyScale如何帮助从您的应用程序和业务中提取更多价值的信息,请随时通过contact@myscale.com与我们联系。



