
随着人工智能的兴起,向量数据库因其高效存储、管理和检索大规模高维数据的能力而受到了广泛关注。这种能力对于处理文本、图像和视频等非结构化数据的人工智能和生成式人工智能(GenAI)应用至关重要。
向量数据库的主要逻辑是提供相似性搜索功能,而不是传统数据库提供的关键字搜索。这个概念在大型语言模型(LLM)的性能提升中得到了广泛应用,特别是在ChatGPT发布之后。
LLM的最大问题是需要大量的资源、时间和数据进行微调,这使得难以保持其更新。这就是为什么当你向LLM查询最近的事件时,它们经常会提供错误的、荒谬的或与输入提示不相关的答案,导致“幻觉”。
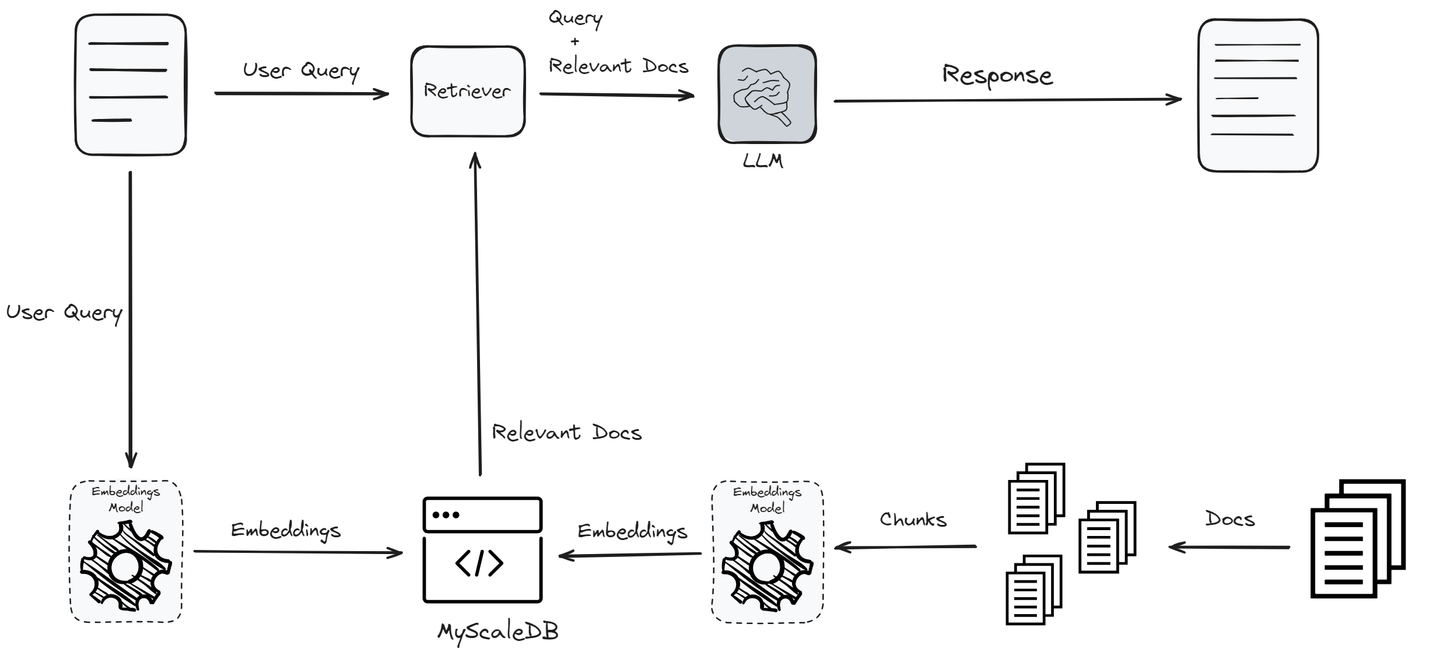
一种解决方案是检索增强生成(RAG) (opens new window),它通过整合从外部知识库检索到的最新信息来增强LLM。专门的向量数据库被设计用于高效处理向量化数据并提供强大的语义搜索功能。这些数据库经过优化,用于存储和检索高维向量,这对于进行相似性搜索非常重要。向量数据库的速度和效率使其成为RAG系统的重要组成部分。
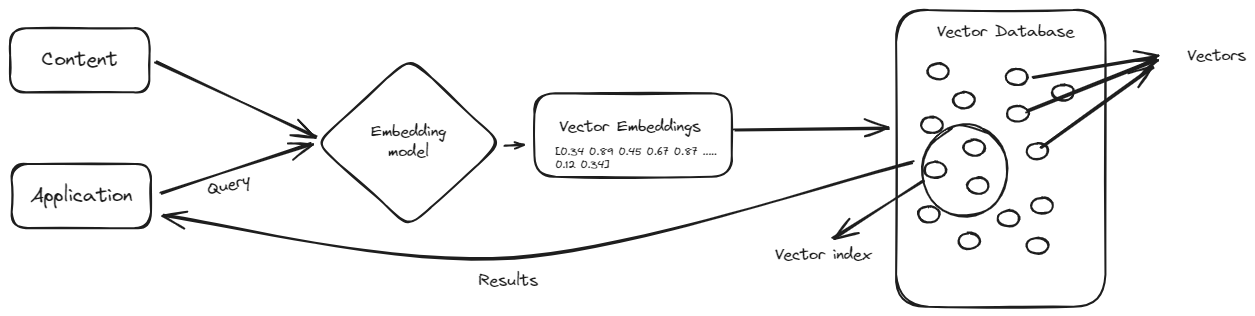
围绕向量数据库的炒作使许多人提出传统数据库可能会被向量数据库取代。你是否可以将一个组织的整个数据集存储在向量数据库中,并使用自然语言而不是编写手动查询来检索它?
但是向量数据库的功能与传统数据库不同。正如Qdrant首席技术官Andrey Vasnetsov所写的那样,“大多数向量数据库在这个意义上并不是数据库。更准确地说,可以称它们为搜索引擎。”这是因为它们的主要目的是提供优化的搜索功能,而不是支持关键字搜索或SQL查询等基本功能。
# 专门的向量数据库的局限性
随着使用案例的增加和人们对应用可扩展性的关注,向量数据库的局限性变得更加明显。开发人员很快意识到,他们仍然需要全文搜索引擎的功能,同时还需要向量搜索。例如,使用向量数据库根据特定条件过滤搜索结果非常困难。这些数据库还缺乏对精确短语的直接匹配,这对于许多任务来说至关重要。
# 对复杂查询的有限支持
复杂查询通常涉及多个条件、连接和聚合,这对于专门的向量数据库来说是具有挑战性的。这些数据库通过元数据过滤提供有限的复杂查询支持。然而,向量数据库中的元数据存储非常有限,这限制了用户进行各种复杂查询的能力。
相比之下,SQL数据库被设计用于处理广泛的存储和处理,可以高效执行涉及多个条件、连接和聚合的复杂查询。这使得SQL数据库在处理复杂数据检索和操作任务时更加灵活和强大。
# 数据类型限制
专门的向量数据库也面临数据类型限制。它们被设计用于存储向量和最少的元数据,这限制了它们的灵活性。这种对向量的关注意味着它们无法处理SQL数据库可以处理的更多种类的数据类型,例如整数、字符串和日期,这使得更复杂和多样化的数据操作成为可能。
总的来说,专门的向量数据库的关注点非常狭窄。它们的架构主要针对语义搜索进行了优化,而不是更广泛的数据管理需求。这限制了它们执行广泛任务的功能。此外,它们无法存储和管理除向量以外的不同数据类型,使其在通用数据库任务方面不太适用。向量数据库适用于RAG应用,但对于更广泛的用例来说,它们的功能不够多样化。
# 集成挑战
将专门的向量数据库集成到现有的IT基础设施中充满了挑战。由于专门的向量数据库与现有系统之间的固有差异,常常会出现兼容性问题,这需要进行大量的数据转换,并可能导致数据丢失或损坏。确保与遗留系统的互操作性以及保持数据的一致性和完整性也是复杂的任务。此外,集成过程需要专门的技能,这在组织内可能不容易获得,导致培训成本高昂和学习曲线陡峭。
此外,集成的财务影响也是巨大的。成本包括软件许可、硬件升级、人员培训和持续维护。此外,现有应用程序可能需要修改或重写以与向量数据库交互,这是一个昂贵且风险高的过程,可能引入新的错误或性能问题。对专门的向量数据库的持续支持和更新需求也可能导致长期的财务承诺。
# 数据处理需要混合方法
专门的向量数据库的基础是向量存储和向量搜索,主要用于RAG应用。然而,传统数据库也应该能够处理向量,并且向量搜索是一种查询处理方法,而不是一种处理数据的新方法的基础。
RAG是一种受欢迎的人工智能技术,受益于向量数据库。虽然向量数据库非常适合语义搜索和处理高维数据,但它们的专注能力往往忽视了组织的运营和功能需求。这可能限制了它们在具有多样化运营和功能需求的更广泛应用中的使用。
同样,传统数据库已经尝试将向量存储和向量搜索功能纳入其中,以提供一种高效的解决方案,用于大规模处理复杂数据类型。例如,PostgreSQL和Elasticsearch引入了向量搜索功能。然而,它们的向量搜索性能不如专门的向量数据库(如Pinecone和Qdrant)好。例如,Qdrant的平均延迟仅为45.23毫秒,精度率为0.9822。相比之下,虽然强大,OpenSearch的延迟更高,为53.89毫秒,精度略低,为0.9823。
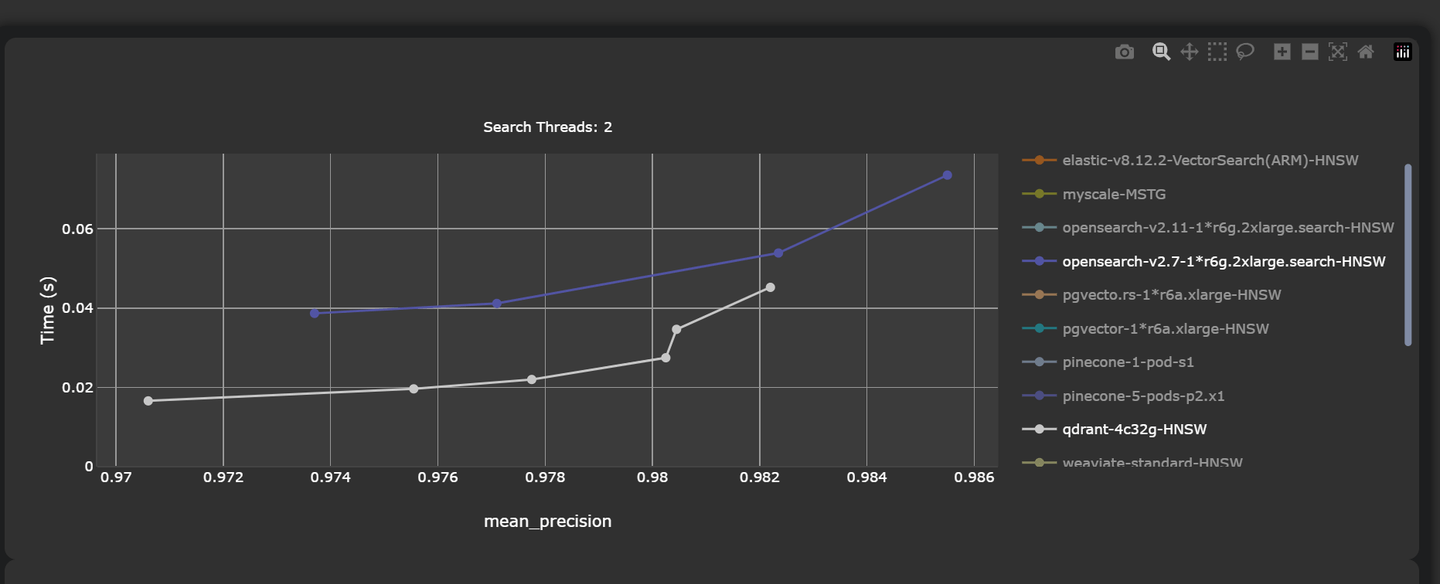
专门的向量数据库的架构专门设计用于高效处理高维向量数据,而传统数据库主要用于关系数据,并不自然地支持向量搜索的特定需求。
另一种选择是将向量扩展添加到当前的数据库或搜索引擎中。这种方法通过将传统数据库的优势和灵活性与现代向量搜索的高级功能相结合,直接支持业务需求。
混合模型可以更贴近企业的多样化数据处理需求,并简化其数据基础设施。这可以降低运营成本和复杂性,最终实现更可扩展和高效的解决方案,满足组织的全面数据处理需求。
# SQL向量数据库弥合差距--介绍MyScaleDB
SQL已经成为可扩展应用程序的支柱已有半个世纪,将其与向量搜索功能集成在一起有望弥合传统和现代数据处理需求之间的差距。将SQL与向量结合起来将提高数据建模的灵活性,并使开发更加容易。这将使系统能够处理涉及结构化数据、向量数据、关键字搜索和跨多个表的连接查询的复杂查询。
虽然专门的向量数据库在处理高维数据时具有精确性和速度方面的优势,但将向量搜索集成到SQL数据库中提供了一种有吸引力的选择。它在复杂数据类型的大规模处理所需的效率和在熟悉和广泛采用的框架内工作的便利性之间提供了平衡。这种集成解决了专门的向量数据库面临的许多挑战,如迭代速度慢、查询效率低和管理单独数据库的高成本。通过采用SQL向量数据库,企业可以利用SQL的可扩展性和可靠性的优势,同时获得处理现代数据处理的多方面挑战所需的高级功能。
MyScaleDB (opens new window)是一个基于ClickHouse的开源SQL向量数据库。它结合了传统SQL数据库的优势和向量数据库的能力,使用SQL来高效存储和管理高维向量,用于GenAI应用。它通过高级过滤和复杂的SQL向量查询提供全面的数据检索,同时支持文本到SQL的使用便捷性。
MyScaleDB比专门的向量数据库更快、更具成本效益 (opens new window),其专有的MSTG索引算法优化了向量数据检索,提高了系统的效率。此外,MyScaleDB在处理各种过滤比例时,在向量增强的SQL/NoSQL数据库中表现出色 (opens new window),具有卓越的性能和可扩展性。

# 结论
完全依赖只处理向量的专门向量数据库会限制数据管理策略的灵活性。多功能或集成的向量数据库提供了更有前途的解决方案。MyScaleDB不仅可以高效地管理向量,还可以作为通用数据库运行,使其成为现代人工智能应用的多功能和强大解决方案。
在当今的人工智能技术世界中,拥有可以管理结构化和向量数据的数据库至关重要。这种方法确保可扩展性、灵活性和成本效益,消除了管理多个系统的需要。通过选择一个多功能的数据库,您可以为未来准备数据基础设施,并满足现代应用程序日益增长的要求。



